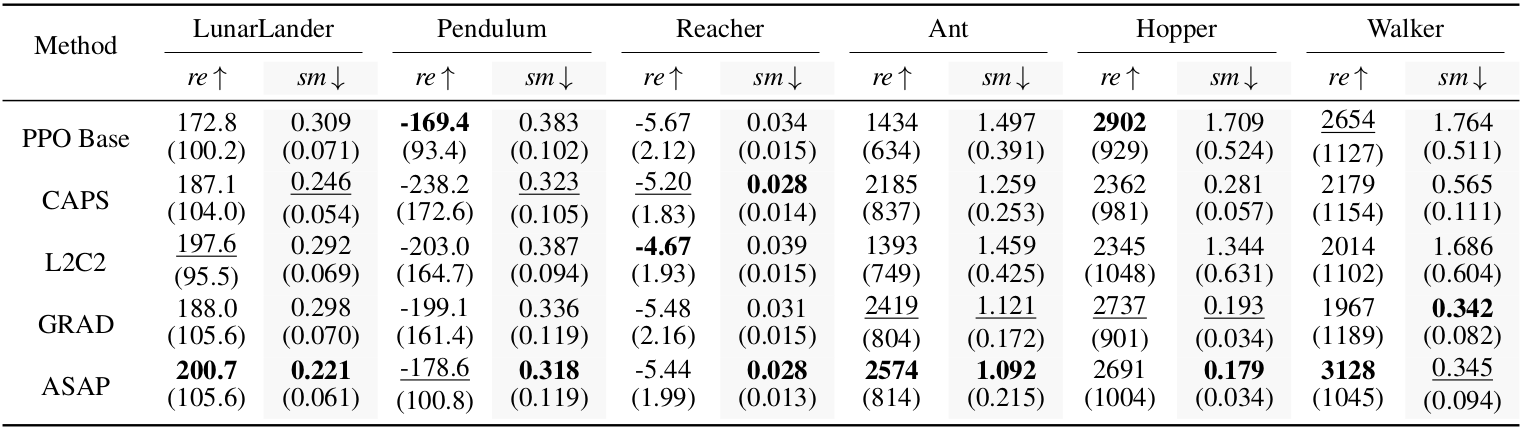
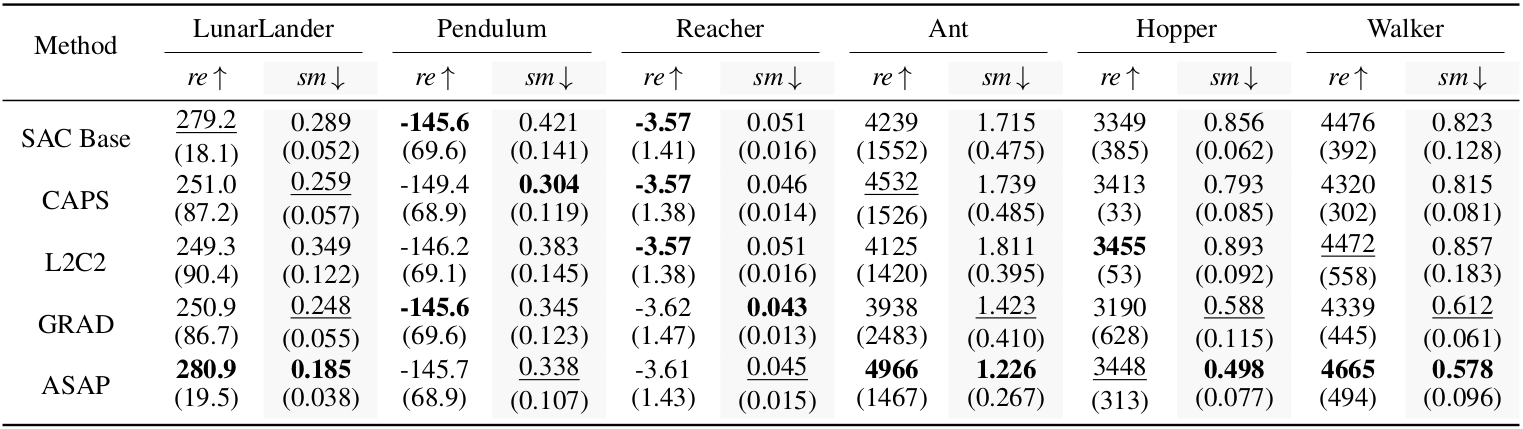
Method
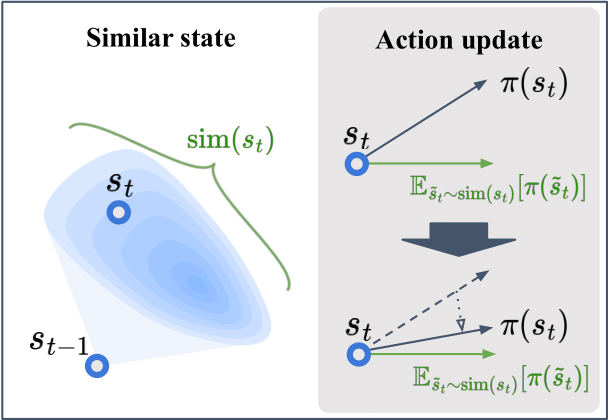
Figure 1. Similar State of ASAP. ASAP uses the environment's transition distribution to define similar states and aligns the action with the expected policy output under this distribution.
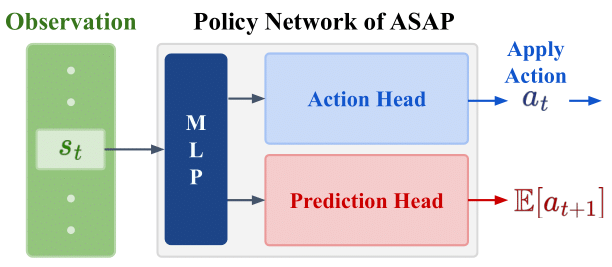
Figure 2. The implementation architecture of ASAP. A prediction head is added after the shared MLP.The prediction head predicts the expected action at time step st+1 given the state at time step st.
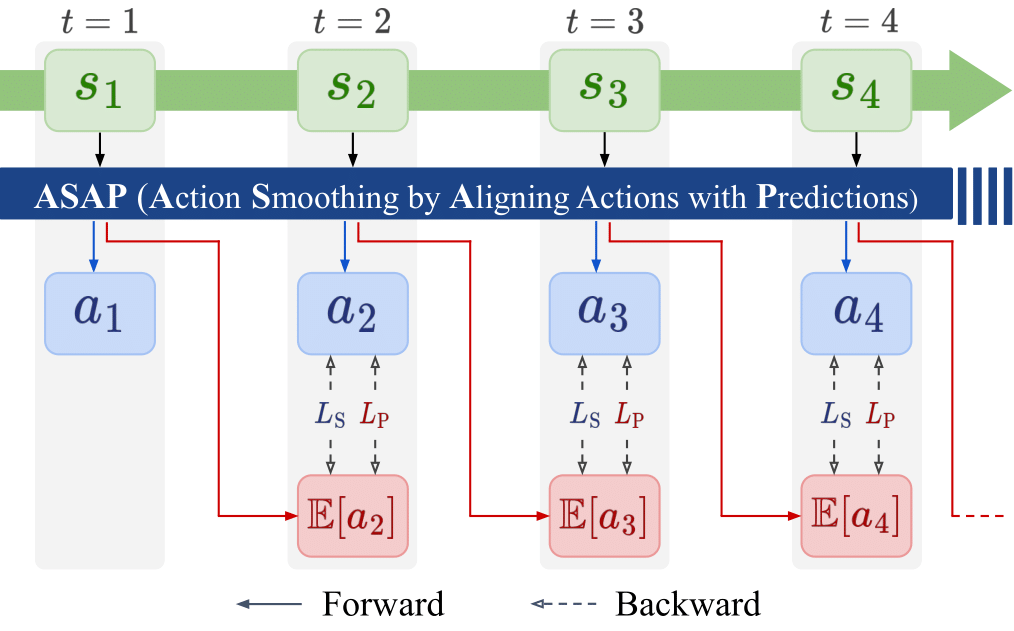
Figure 3. The update procedure of ASAP. The ASAP network takes st as input and outputs both the executed action at and the predicted expected action at the next state, E[at+1]. The action head is trained to match the output of the prediction head, while the prediction head learns the expected next action over the state distribution stored in the buffer.
Similar State Based on Transition Distribution
A key challenge in action smoothing for reinforcement learning lies in defining similar states in a way that faithfully reflects the underlying system dynamics. Prior loss-based approaches typically rely on heuristic or synthetic neighborhoods, such as Gaussian perturbations around the current state or interpolations along the next-state direction. However, these artificially generated states often deviate from the true state distribution induced by the environment, leading to unstable or overly conservative regularization.
ASAP addresses this limitation by defining similar states directly from the environment’s transition distribution. Given a previous state st−1, we define the similar state distribution as the set of next states sampled from the transition kernel P(· | st−1). Intuitively, states that originate from the same preceding state are expected to be similar from a dynamics perspective, as their differences arise solely from bounded stochastic disturbances.
Under mild assumptions on the transition function—namely, local Lipschitz continuity with respect to noise and bounded stochastic perturbations—this transition-induced definition forms a spatially bounded neighborhood. As a result, it provides a principled foundation for enforcing local Lipschitz continuity of the policy without introducing synthetic samples or heuristic distance thresholds.
Within this framework, ASAP enforces action consistency by aligning the policy output at the current state with the expected action over the similar state distribution. This alignment suppresses excessive sensitivity to small state variations and directly mitigates oscillatory behavior caused by transition noise.
Action Smoothing via Predictions from Preceding States
Building on the transition-induced similar state formulation, ASAP introduces a practical mechanism to enforce action smoothness during training. Instead of explicitly sampling multiple next states, ASAP augments the policy network with an additional prediction head that estimates the expected action at the next time step given the preceding state.
Specifically, the ASAP actor consists of a shared feature extractor followed by two heads: an action head that outputs the executed action at from the current state st, and a prediction head that predicts the expected next action E[at+1 | st]. The action head is trained to align its output with the prediction head, thereby encouraging consistency across transition-induced similar states.
To stabilize training, ASAP separates the learning signals for the two heads using stop-gradient operations. The prediction head learns to approximate the policy’s actual outputs, while the action head treats the predicted action as a fixed target. This asymmetric design avoids moving-target instability and enables robust optimization.
In addition to spatial alignment, ASAP incorporates a temporal regularization term that penalizes second-order differences in the action sequence. This temporal loss suppresses high-frequency oscillations while preserving the agent’s ability to perform rapid but purposeful action changes when necessary.
The final ASAP objective combines the standard reinforcement learning actor loss with spatial and temporal smoothness terms. As a result, ASAP achieves smooth and stable control policies without modifying the network architecture at inference time, making it readily applicable to real-world robotic systems.
ASAP Objective Function
Formally, ASAP optimizes the policy using a composite objective that combines the standard reinforcement learning actor loss with spatial and temporal smoothness penalties:
$$ J^{\mathrm{ASAP}}_{\pi_\phi} = J_{\pi_\phi} + \lambda_S L_S + \lambda_P L_P + \lambda_T L_T $$
Here, Jπφ denotes the standard actor loss used in common RL algorithms such as PPO and SAC. The additional terms encourage smoothness in both the spatial and temporal domains.
The spatial smoothing loss aligns the action produced at the current state with the expected action predicted from the preceding state:
$$ L_S = \left\| \pi_\phi(s_t) - \texttt{stopgrad}\!\left(\pi_P(s_{t-1})\right) \right\|_2^2 $$
To train the prediction head, ASAP introduces a complementary prediction loss, which encourages the predicted action to match the policy’s actual output while treating the target as fixed:
$$ L_P = \left\| \pi_P(s_{t-1}) - \texttt{stopgrad}\!\left(\pi_\phi(s_t)\right) \right\|_2^2 $$
This asymmetric design decouples the learning dynamics of the action head and the prediction head, preventing moving-target instability and allowing each component to be optimized with an appropriate learning strength.
In addition to spatial alignment, ASAP adopts a temporal smoothness penalty based on second-order action differences, originally proposed in Grad-CAPS:
$$ L_T = \left\| \frac{a_{t+1} - 2a_t + a_{t-1}} {\tanh(a_{t+1} - a_{t-1}) + \epsilon} \right\|_2^2 $$
This temporal loss suppresses high-frequency oscillations while preserving flexibility for purposeful action changes. The hyperparameters λS, λP, and λT control the relative strength of each regularization term.