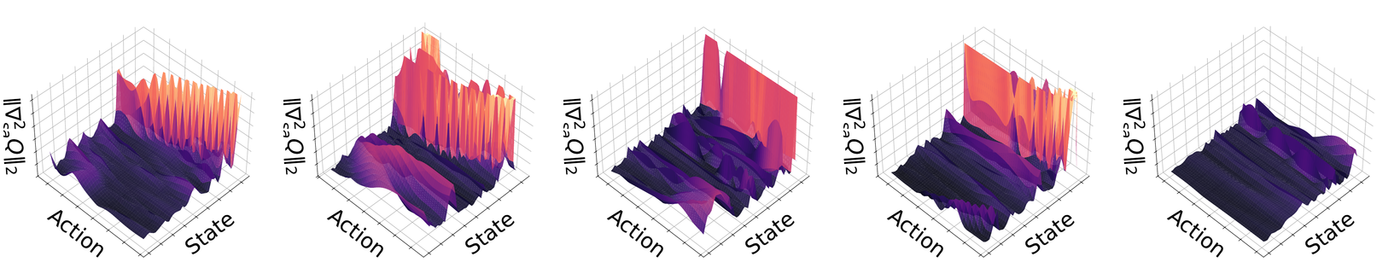
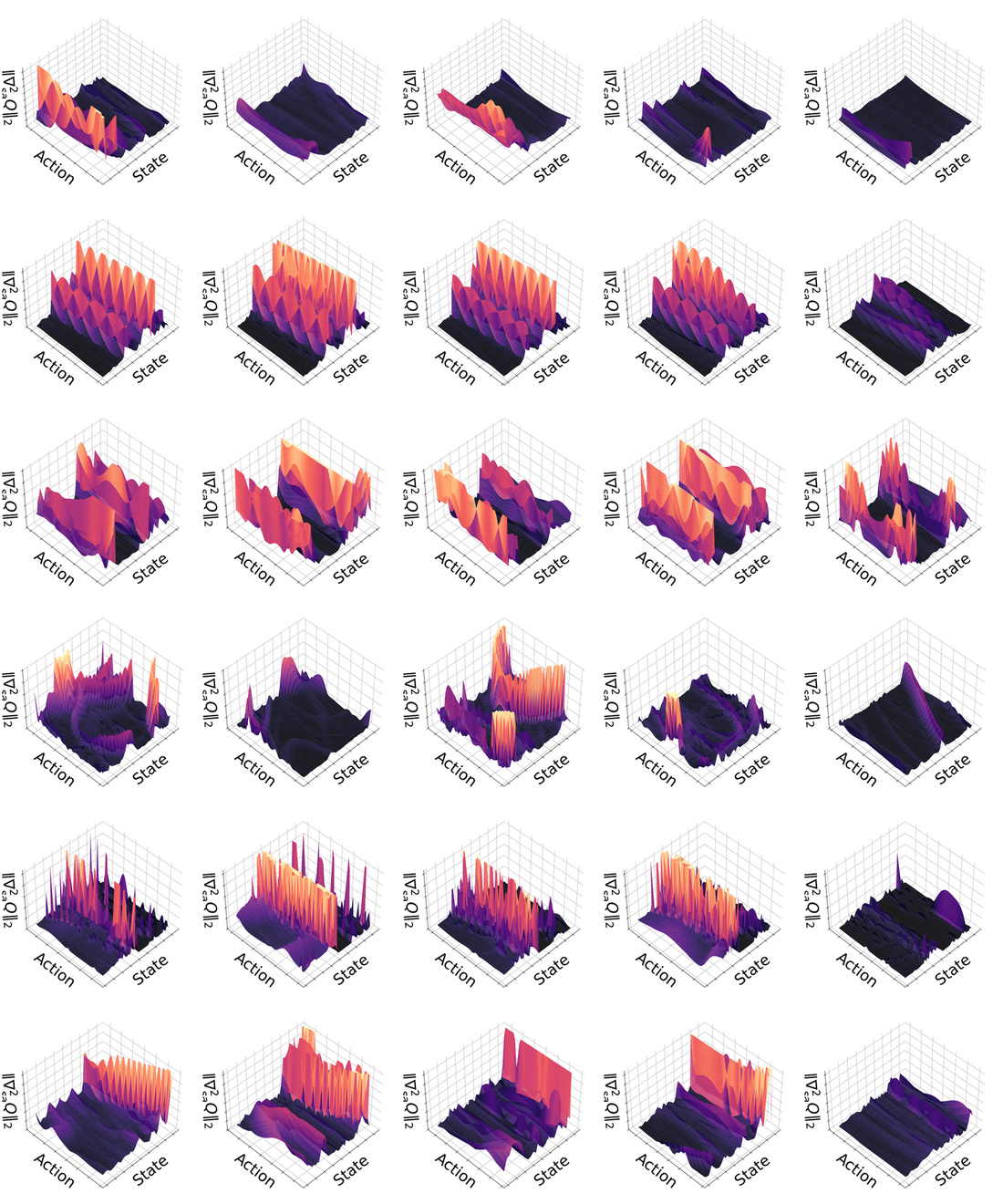
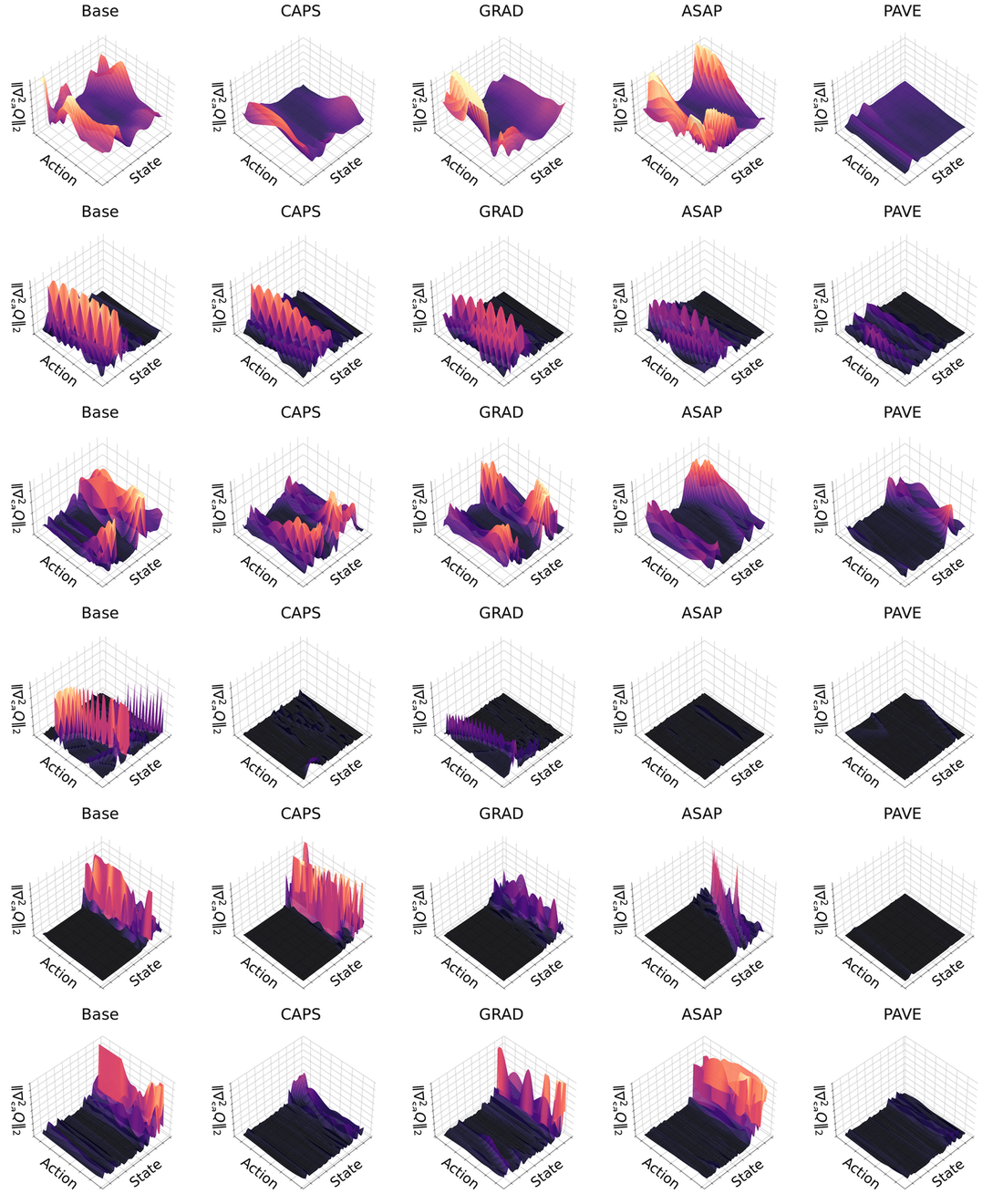
Method
Theoretical Analysis: The Geometry of Policy Sensitivity
To remediate the fundamental origin of action instability in actor-critic methods, we analyze how the
differential geometry of the value function dictates the behavior of the induced policy. We derive the
sensitivity of the greedy policy $a^{*}(s) = \arg\max_{a} Q(s, a)$ with respect to state perturbations and
show, via the Implicit Function Theorem (IFT), that policy smoothness is governed by specific Hessian terms
of the critic.
Implicit Policy Definition and Sensitivity Derivation
In the actor-critic paradigm, the actor $\pi_\phi(s)$ is optimized to approximate the maximizer of the
Q-function. Even when the actor is a neural network, its update direction is fundamentally driven by
$\nabla_a Q(s,\pi_\phi(s))$. The geometric regularity of the explicit maximizer
$a^{*}(s) = \arg\max_{a} Q(s, a)$ therefore imposes a fundamental limit on the learned policy:
$\pi_\phi$ cannot be smoother than $a^{*}$ without deviating from the optimal action.
Lemma 1 (Implicit Policy Jacobian).
Let $Q : \mathcal{S} \times \mathcal{A} \to \mathbb{R}$ be twice continuously differentiable. Assume that
for a given state $s$, $a^{*}(s)$ is a strict local maximum and an interior point of $\mathcal{A}$, so that
the action Hessian $\nabla^{2}_{aa} Q(s, a^{*}(s))$ is negative definite. Then the policy Jacobian
$J_{\pi}(s) = \nabla_s a^{*}(s)$ is given analytically by
$$
J_{\pi}(s) \;=\; -\bigl[\nabla^{2}_{aa} Q(s, a^{*}(s))\bigr]^{-1}\, \nabla^{2}_{sa} Q(s, a^{*}(s)).
$$
Proof.
Since $a^{*}(s)$ is an interior extremum, it satisfies the first-order optimality condition
$\nabla_a Q(s, a^{*}(s)) = 0$. Treating this as a vector-valued mapping $G(s, a(s)) = 0$, the total
derivative with respect to $s$ gives, by the chain rule,
$$
\nabla^{2}_{sa} Q(s, a^{*}(s)) \;+\; \nabla^{2}_{aa} Q(s, a^{*}(s))\, \nabla_s a^{*}(s) \;=\; 0.
$$
By the strict-concavity assumption, $\nabla^{2}_{aa} Q(s, a^{*}(s))$ is invertible. Pre-multiplying by its
inverse yields the stated formula. $\blacksquare$
Geometrically, policy sensitivity is the product of an inverse curvature term and a
mixed-partial coupling term: $\nabla^{2}_{sa} Q$ acts as a forcing term that dictates how the
ascent direction shifts under state perturbations, while $[\nabla^{2}_{aa} Q]^{-1}$ acts as an
amplification factor determined by the flatness of the landscape. If the Q-surface is flat (low curvature),
the inverse Hessian explodes, rendering the policy hypersensitive to even negligible gradient rotations.
Spectral Bounds on Lipschitz Continuity
Proposition 2 (Lipschitz Continuity Bound).
Let $\|\cdot\|_2$ denote the spectral norm. Suppose
$\|\nabla^{2}_{sa} Q(s, a^{*}(s))\|_2 \le M$ and the action Hessian satisfies the strict concavity
condition $\lambda_{\max}(\nabla^{2}_{aa} Q(s, a^{*}(s))) \le -\mu < 0$. Then the induced greedy policy is
Lipschitz continuous with constant $L$ satisfying
$$
\|a^{*}(s) - a^{*}(s')\|_2 \;\le\; L\, \|s - s'\|_2,
\qquad
L \;\le\; \frac{M}{\mu}.
$$
Proof.
Apply the spectral norm to the policy Jacobian from Lemma 1 and use sub-multiplicativity:
$$
\|J_\pi(s)\|_2 \;\le\; \bigl\|[\nabla^{2}_{aa} Q]^{-1}\bigr\|_2 \cdot \|\nabla^{2}_{sa} Q\|_2 .
$$
(i) Curvature bound. The assumption $\lambda_{\max}(\nabla^{2}_{aa} Q) \le -\mu$ places the
spectrum of the Hessian inside $(-\infty, -\mu]$. The eigenvalues of the inverse Hessian are therefore
bounded in magnitude by $1/\mu$, giving
$\bigl\|[\nabla^{2}_{aa} Q]^{-1}\bigr\|_2 \le 1/\mu$.
(ii) Mixed-partial bound. By hypothesis, $\|\nabla^{2}_{sa} Q\|_2 \le M$.
Substituting and taking the supremum over $s$,
$L \triangleq \sup_{s} \|J_\pi(s)\|_2 \le M/\mu$. The Mean Value Inequality for vector-valued
differentiable functions then gives
$\|a^{*}(s) - a^{*}(s')\|_2 \le L\,\|s - s'\|_2 \le (M/\mu)\,\|s - s'\|_2$. $\blacksquare$
Theoretical implication. The bound $L \le M/\mu$ shows that simply minimizing the gradient variance
(reducing $M$) is insufficient if the curvature $\mu$ also vanishes. Conventional regularizers tend to
flatten the Q-landscape, driving $\mu \to 0$, which can theoretically explode the sensitivity term
$\|[\nabla^{2}_{aa} Q]^{-1}\|$. PAVE is explicitly formulated to minimize $M$ while ensuring that $\mu$
stays strictly bounded away from zero.
PAVE: Policy-Aware Value-field Equalization
PAVE directly enforces the geometric stability conditions derived above. Instead of constraining the actor,
PAVE regularizes the critic to minimize the Lipschitz bound $L \le M/\mu$ and to enforce
trajectory consistency. This is achieved by three synergistic objectives: (1) suppressing noise sensitivity
($M$) via Mixed-Partial Regularization, (2) aligning temporal vector fields via Vector Field
Consistency, and (3) preserving curvature ($\mu$) via Curvature Preservation to prevent
geometric collapse. The losses below are finite-difference proxies that incentivize the desired
geometric properties rather than guaranteeing them.
Mixed-Partial Regularization (MPR)
To minimize the numerator $M$ in the Lipschitz bound, we suppress the magnitude of $\nabla^{2}_{sa} Q$.
Direct construction of the mixed Hessian costs $\mathcal{O}(d^{2})$, which is prohibitive online. We
instead use a finite-difference proxy grounded in a Taylor expansion. Considering a small state
perturbation $\epsilon$,
$$
\nabla_a Q(s+\epsilon, a) \;=\; \nabla_a Q(s, a) + \nabla^{2}_{sa} Q(s,a)\,\epsilon + \mathcal{O}(\|\epsilon\|^{2}),
$$
so $\|\nabla_a Q(s+\epsilon, a) - \nabla_a Q(s, a)\|$ is an efficient proxy for the Hessian-vector product
$\|\nabla^{2}_{sa} Q\,\epsilon\|$. This motivates
$$
\mathcal{L}_{\mathrm{MPR}}(\theta)
\;=\;
\mathbb{E}_{\substack{(s,a)\sim\mathcal{D}\\ \epsilon \sim \mathcal{N}(0,\sigma^{2}I)}}
\Bigl[\;
\bigl\| \nabla_a Q(s+\epsilon, a) - \nabla_a Q(s, a) \bigr\|_2^{2}
\;\Bigr].
$$
Formal justification. Substituting the linear approximation and integrating over the isotropic
Gaussian noise $\epsilon$,
$$
\mathcal{L}_{\mathrm{MPR}} \;\approx\;
\mathbb{E}_\epsilon\!\left[\,\epsilon^{\top} (\nabla^{2}_{sa} Q)^{\top} (\nabla^{2}_{sa} Q)\, \epsilon\,\right]
\;=\; \sigma^{2}\,\|\nabla^{2}_{sa} Q\|_F^{2}.
$$
Since the spectral norm is upper-bounded by the Frobenius norm ($\|A\|_2 \le \|A\|_F$), minimizing
$\mathcal{L}_{\mathrm{MPR}}$ encourages a smaller upper bound on $M$.
Vector Field Consistency (VFC)
MPR enforces spatial smoothness via isotropic perturbations, but stable robotic control also requires
temporal coherence along trajectories. Interpreting $\nabla_a Q(s, a)$ as the score function of an
implicit Boltzmann policy $p(a\mid s) \propto \exp(Q(s,a))$, we frame temporal stability as minimizing the
distributional shift of the policy across consecutive states — a Fisher-divergence-style objective:
$$
\mathcal{L}_{\mathrm{VFC}}(\theta)
\;=\;
\mathbb{E}_{(s_t, a_t, s_{t+1}) \sim \mathcal{D}}
\Bigl[\;
\bigl\| \nabla_a Q(s_t, a_t) - \nabla_a Q(s_{t+1}, a_t) \bigr\|_2^{2}
\;\Bigr].
$$
Formal justification. Using the first-order expansion $s_{t+1} \approx s_t + \Delta s_t$,
$$
\bigl\|\nabla_a Q(s_{t+1}, a_t) - \nabla_a Q(s_t, a_t)\bigr\|_2^{2}
\;\approx\;
\bigl\|\nabla^{2}_{sa} Q(s_t, a_t)\, \Delta s_t\bigr\|_2^{2}.
$$
Whereas MPR reduces $M$ globally, VFC encourages a smaller $M$ specifically along the state transitions
imposed by the environment dynamics ($\nabla^{2}_{sa} Q\,\Delta s_t$). This mitigates the "chattering"
effect caused by conflicting gradients at adjacent timesteps.
Curvature Preservation (Curv)
Minimizing $\mathcal{L}_{\mathrm{MPR}}$ in isolation introduces a pathological risk: the network may
collapse $Q$ to a trivial flat plane (i.e.\ $\nabla_a Q \approx 0$ everywhere) to satisfy the smoothness
penalty. By Proposition 2, if $Q$ becomes flat, $\|[\nabla^{2}_{aa} Q]^{-1}\|$ diverges, paradoxically
amplifying policy sensitivity. To preclude this "over-smoothing" collapse, we enforce a curvature lower
bound:
$$
\mathcal{L}_{\mathrm{Curv}}(\theta)
\;=\;
\mathbb{E}_{\substack{(s,a) \sim \mathcal{D}\\ v \sim p(v)}}
\Bigl[\;
\max\!\bigl(0,\; v^{\top} \nabla^{2}_{aa} Q(s, a)\, v + \delta \bigr)
\;\Bigr],
$$
where $\delta > 0$ is the minimum required sharpness. Computational efficiency is preserved by Hutchinson's
trace estimator with random Rademacher vectors $v$. To enable a valid Hessian computation we use SiLU
activations in the critic to ensure $C^{2}$ continuity.
Formal justification. This regularizer explicitly targets the denominator $\mu$ in the Lipschitz
bound $L \le M/\mu$. By penalizing projected curvature values $v^{\top} \nabla^{2}_{aa} Q\, v$ that exceed
$-\delta$, this objective incentivizes concavity via Hutchinson's trace estimator, which controls the
trace rather than individual eigenvalues. This encourages the maximum eigenvalue to remain negative,
helping to keep the inverse Hessian norm bounded and reducing sensitivity.
Total Objective
The composite objective for the critic parameter $\theta$ is a weighted sum of the standard temporal-difference
regression loss and the three geometric regularizers:
$$
\mathcal{L}(\theta)
\;=\;
\mathcal{L}_{\mathrm{TD}}(\theta)
\;+\; \lambda_{1}\, \mathcal{L}_{\mathrm{MPR}}(\theta)
\;+\; \lambda_{2}\, \mathcal{L}_{\mathrm{VFC}}(\theta)
\;+\; \lambda_{3}\, \mathcal{L}_{\mathrm{Curv}}(\theta).
$$
Crucially, these geometric regularizers are applied solely as auxiliary losses to the critic. The
actor update mechanism remains unchanged, using standard policy gradients while benefiting from the paved,
well-conditioned Q-gradient landscape.